GEN: Typically, image analysis tools are greatly influenced by inconsistent staining results and even different techniques used for multiplexing. How does the software used by OracleBio account for inter- and intra-run variability in staining quality?
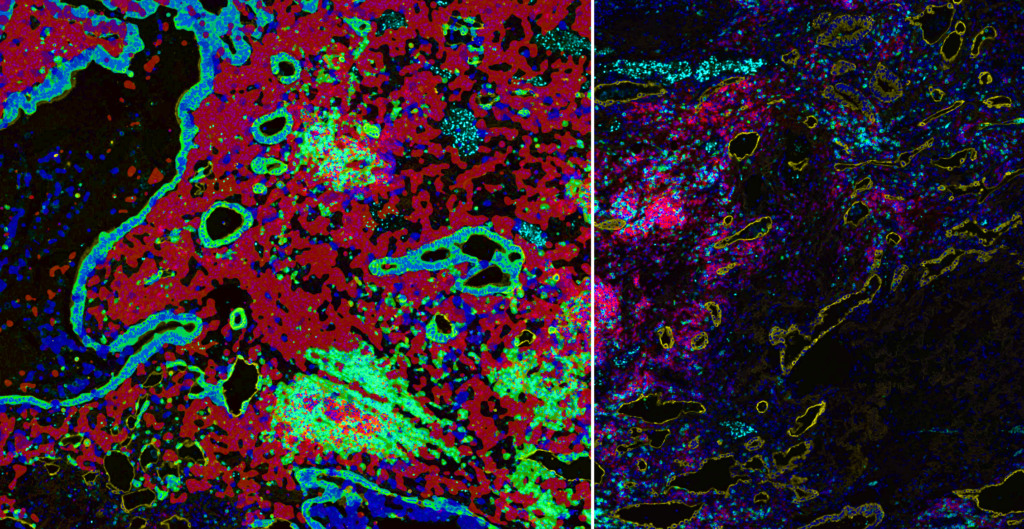
Lorcan. To be honest, we do see staining variability in some sample sets, especially in complex tissues from large clinical sample sets of images. That staining variance can come in through some pre-analytical steps that can come from the tissue, assay etc. So, when we get the images for image analysis, yes, there’s a number of things that may already have happened at the pre-analytical stage that we can’t solve, but we can solve some levels of variance within the algorithms we’ve developed. We do this using AI deep learning approaches in our algorithm development.
For example, if we’re looking at something like tumor stroma segmentation with a tissue classifier and we’re using the cytokeratin layer and DAPI to train the deep learning algorithm, then if we have, say, 100 images in the study and we want to use 20 of those images to train an algorithm, we will export the actual mean intensity for the cytokeratin channel from each of the hundred images. We will look at each of the 100 images and look for those images where there is quite a high mean intensity, which means there’s more intense staining. For the images that are low intensity or have low levels of staining present, we will make sure that they’re both included in the training image set for the deep learning algorithms so that we’re exposing the algorithm to this range of variance that we may see in a sample set.
From a cell detection perspective, a very similar approach is taken where if we’re detecting e.g., CD68 cells or CD3 cells in an algorithm specifically as a top line lineage, we will look across the whole image set during the algorithm development stage. We will identify those images where the staining is weaker, or the staining is stronger based on the mean intensity across the tumor microenvironment, and we’ll make sure that those images are included. Of course, a mean intensity can tell you two things: It can tell you that generally all the cells are staining low, or it may tell you that there’s a bunch of cells there that are staining really well, but there’s just less of them, so we do need to take that into context.
In summary, I would say that by incorporating a deep learning approach into the algorithm development, we are moving away from a more standard threshold approach, where we choose a single threshold and then try and apply that to a large set of images where we may see variance. Instead, by using deep learning, we are starting to move more to an adaptive threshold approach. I think with this it does allow us to manage some of the variance that we see in these types of images. We’re moving from single chromogenic, where there was only one or two channels of interest and DAB staining, to now four, 8, 12 plex and higher where there’s multiple channels with variance in each channel. So yes, I think AI deep learning has been a big help in helping manage some of that variance.
GEN: Will we ever be able to come to a consensus on best practices for AI driven digital pathology? Or is this strictly tumor or tissue dependent?
Lorcan: Yes, I think when we talk about AI and digital pathology, it’s such a dynamic space now and there is so much ongoing development in the assays that we are seeing coming through. As I said in my presentation, this comes from all the updated scanning capabilities to the available information in the images and the strength and power of these neural networks.
But let’s not forget that the abilities of these neural networks may be very different in a couple of years’ time, so we are dealing with a very dynamic, moving landscape. With that in mind, to pin down best practices can be quite challenging. To date the algorithms developed are very much focused around answering specific questions, e.g., dealing with segmentation of tumor-stroma and identification of cells.
I think as our knowledge and use of AI develops and as we move to identifying more biological or spatial signatures from clinical sets, and that information moves more towards a diagnostic endpoint or gets closer to specific use with the patient, then I do think best practices will really come much sharper into focus. And regarding things like how do we standardize the development of these apps? I think at the moment it’s just a really dynamic area. Certainly, this is something that needs to be established to get us closer to the patient with these services and technologies.
GEN For the deep learning algorithm with additional H&E layer, is that a serial section or the same exact section used for the multiplex IF?
The images that we get from Ultivue have the RGB single channels built into the TIFF image, and they can be switched on to create the H&E images which is a real benefit not just to us, but as I said in my presentation, also to pathologists who are working on these image
Lorcan Sherry
CSO & Co-founder of OracleBio
Lorcan: Short answer, yes. It’s the same section, and from a digital pathology image analysis perspective, it is so valuable to have that H&E built into the same section. This is something that Ultivue have really taken on and tried to standardize in how they present their images for subsequent in-depth image analysis. And bear in mind, while you can certainly take serial sections and you can certainly align serial sections, you’re really not able to completely align the data. This may be okay for tissue classification purposes. But if you’re looking for specific cell identification with H&E or are trying to support algorithm development from a cell detection perspective with the H&E component of the image, it does become more challenging when you’re trying to use a serial section co-registered to a multiplex image. The images that we get from Ultivue have the RGB single channels built into the TIFF image, and they can be switched on to create the H&E images which is a real benefit not just to us, but as I said in my presentation, also to pathologists who are working on these images.
Gen: How do you analyze high plex images, say 30 to 40 markers? Do you use manual thresholding for each marker?
Lorcan: Obviously, these approaches can be quite complex with respect to high plex assays, especially going up to 30 or 40. I think, with how we use deep learning algorithms at the minute, it’s also to do with the number of channels that you can use within the neural network and that can be used to train a neural network.
A lot of neural networks are trained on traditional RGB images, which restricts them to three channels for deep learning purposes. We can certainly use AI as an approach for some of those markers around, say, accurate segmentation of cells, using nuclear markers, or T cell or macrophage lineage markers. Then we can use a manual thresholding approach for several of the other markers. You can either take all these efforts and try to build it all out into one algorithm, or the other option is that you use several different algorithms on a high plex image so that you specifically develop AI maybe for three or four markers of interest. You create data for those three or four markers, and you set up a number of algorithms that are AI based. Then you export the data for each of these algorithms and combine it to do post-processing for spatial analysis.
So, there’s different ways to do this, and it really depends on how much you want to frontload different algorithm approaches and try and incorporate an adaptive approach. Alternatively, you may want to combine AI with manual thresholds. For us as a company and what we provide as a service, we must also take into consideration overall time and turnaround time, as well as cost. Ultimately, there will be components where we will potentially combine, say, AI with manual approaches for large cohorts and high plex image analysis.
Gen: What is the limitation of using open-source software compared with licensed image analysis software? Can the data be reliable?
Lorcan: Yes, that’s a good question. I can only really speak from our perspective as a contract research organization. We have traditionally used commercially available software. We use Visiopharm and Indica Labs Halo. We have service contracts with those companies which really gives us confidence that the software is getting developed in the correct way. It’s validated by them. Any potential bugs that may arise we can turn over to their respective service teams to get those bugs fixed and get back on track quickly. So the end product is good, and ultimately we have confidence that the data coming out of the software is going to be accurate and robust, in line with our client’s expectations.
On the flip side of the coin, we are in such a dynamic area that we do know there is never going to be one software that will answer or solve all the questions. I did mention that we do some Python scripting and MATLAB capabilities in-house, and I know there are a number of open-source software that are being extensively used from a research perspective to really drive forward the understanding of spatial biology. I would say to people, yes, you absolutely can use those. Specifically, if you bring them internally, you can do some level of validation, you’re comfortable and confident that they are acting accordingly, and your data is robust, then these contributions may help move data forward and help identify spatial signatures.
Ultimately, I think it’s a question that is probably quite specific to whatever individual and their circumstances that are used. I’m not going to say you shouldn’t use open-source software by any stretch, but from a commercial perspective, it’s important for us to also have the reliability of service arms behind us that we can rely on to help us with any issues.
If you have any questions, or would like more information on some of the topics discussed during this Q&A session, please look through our scientific content available in our resource center, https://ultivue.com/resource-center
hafadmin Categories: Uncategorized Tags: digital pathology, multiplex image analysis, Points of VUE, tumor microenvironmentYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from HubSpot. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Hubspot Meetings. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Instagram. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information
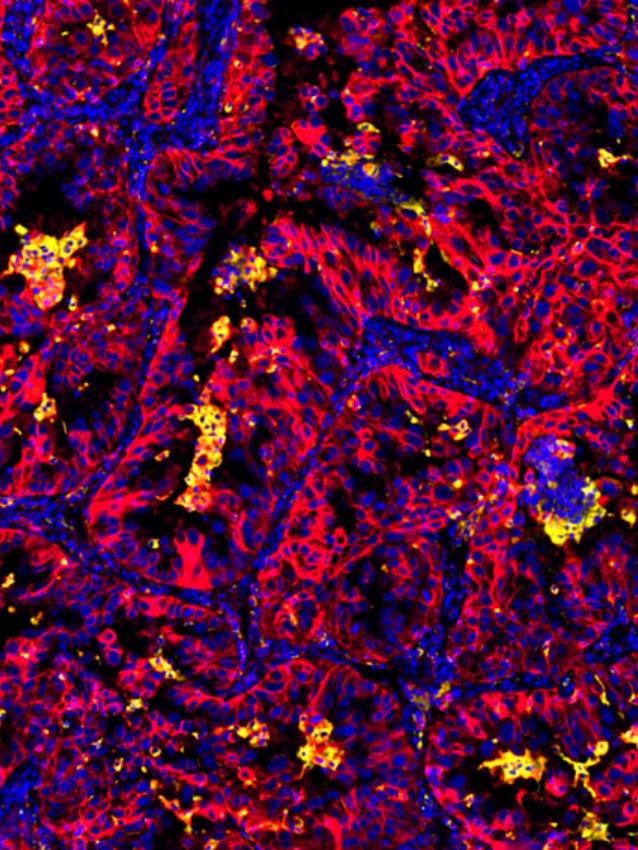
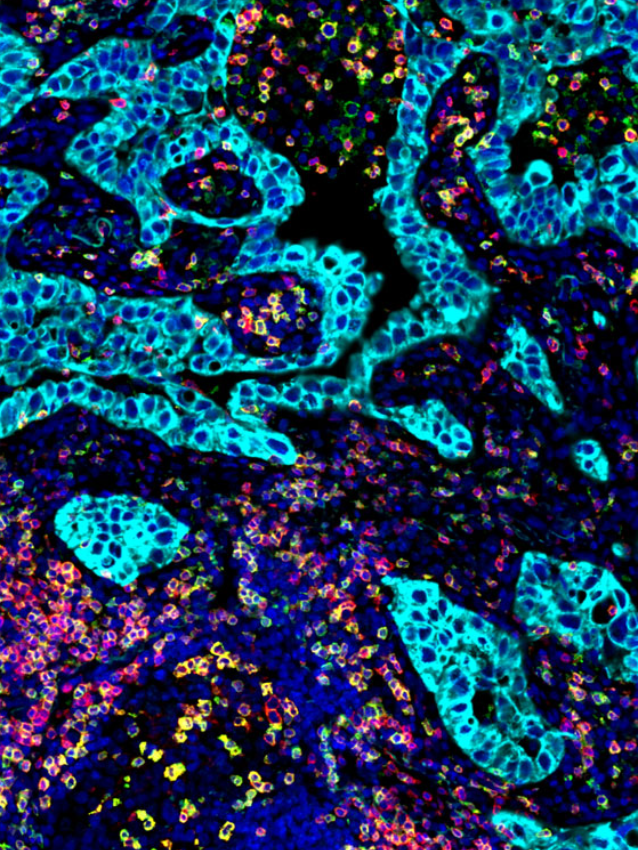
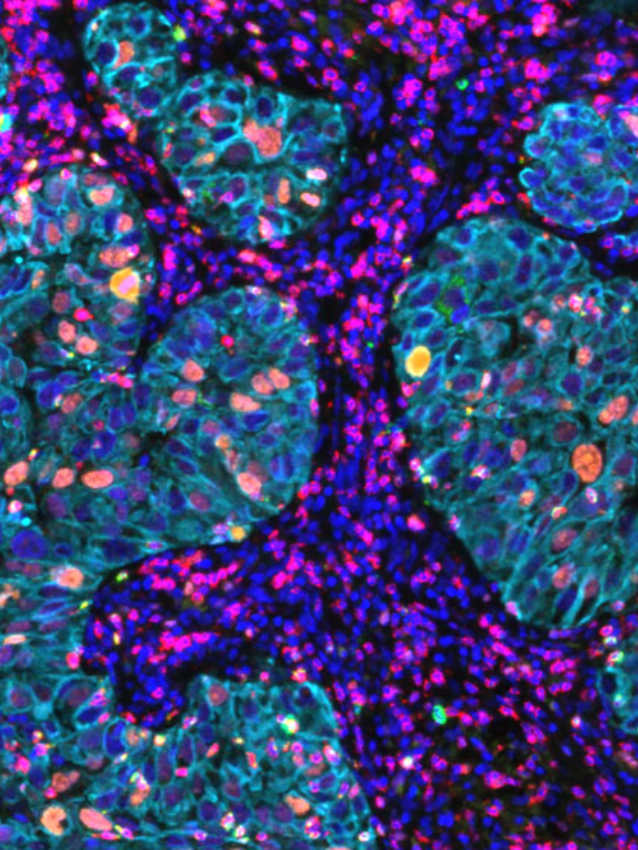


 digital pathology
6535
Living in a Spatial World Q&A, Part 2
digital pathology
6535
Living in a Spatial World Q&A, Part 2
